Evaluating Elicit’s Systematic Literature Review Capabilities

1 min read

Last year, Elicit launched an end-to-end systematic review workflow as part of our mission to radically increase good reasoning.
We've added new features along the way and also spent considerable time upgrading the models behind the system — how it searches, how it applies screening criteria, how it extracts data, and how it reasons through each decision. Today we're publishing how we evaluated whether that work translated into the rigor systematic reviews demand.
Data collection
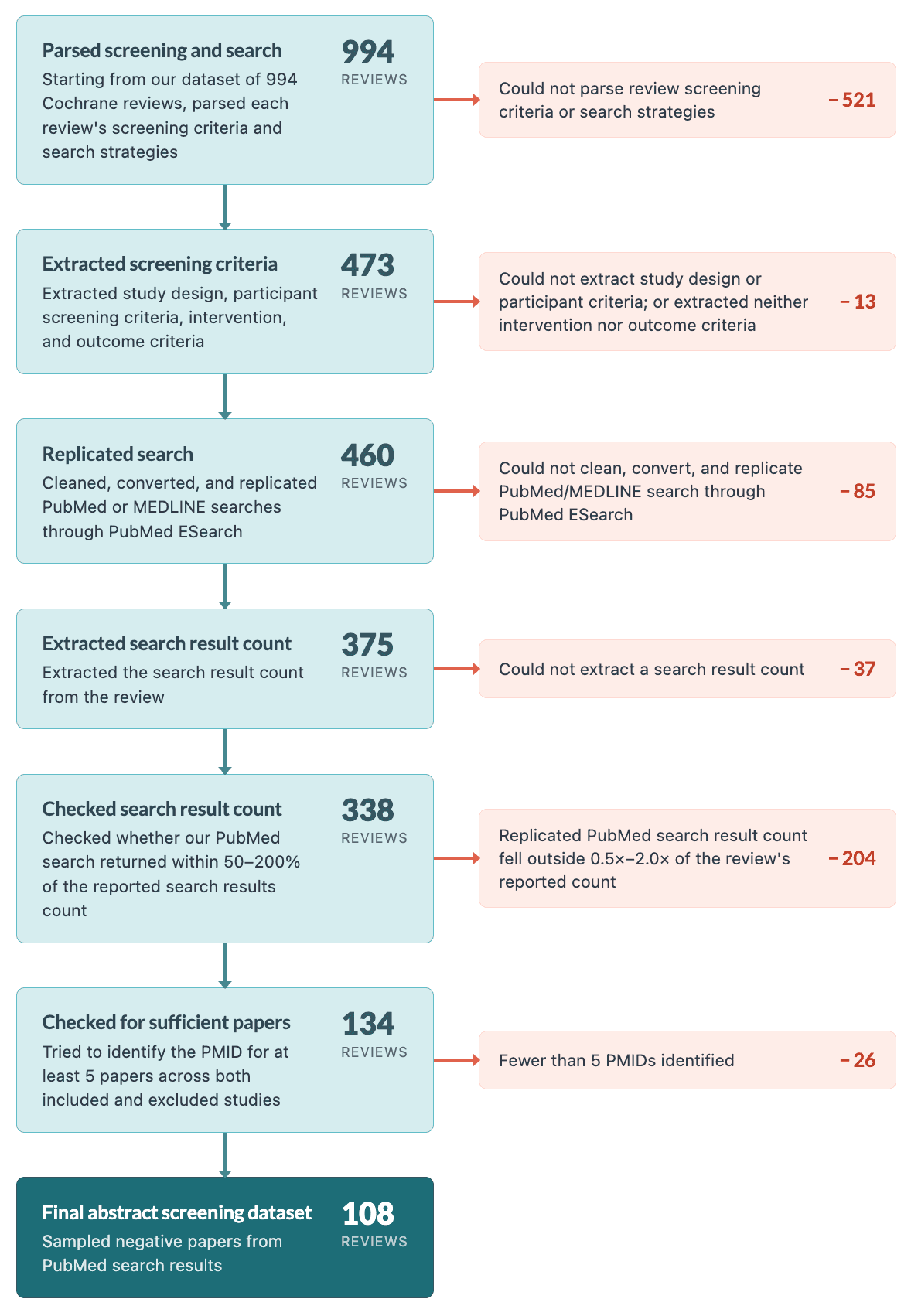
In order to rigorously evaluate Elicit’s performance across all phases, we knew we had to collect a large set of gold standard systematic reviews. We built a ground truth dataset from open-access Cochrane reviews — Cochrane reviews are widely considered the gold standard for evidence synthesis in health, medicine, and beyond. We sampled 1,000 reviews, balanced by round-robin sampling across 12 MeSH areas (Hematologic, Neurology, Digestive, Immunologic, Infectious Disease, Musculoskeletal, Eye, Endocrine/Metabolic, Respiratory, Neoplasms, Cardiovascular, and Kidney), yielding roughly 83–84 reviews per area. After dropping duplicates, we were left with 994 unique reviews covering 38,493 study records.
A study record is the entry for the study in the review’s characteristics of included studies or characteristics of excluded studies section, usually named with a short label like “Smith 2018.” It is not the same thing as a paper. A single study record can point to one paper or to several papers, e.g. the main trial report, a conference abstract, and a follow-up analysis. We resolved each study record to a single representative paper where we could do so confidently and dropped those studies where we could not.
We first matched each study record to the corresponding entry in the references section. This worked for almost every listed study: 99.9% had at least one entry in the references section, and 87.7% could be matched to one unambiguous paper. However, only 58.4% of listed studies had a DOI present in the references section, so DOI-based search scoring necessarily covers a subset of the full dataset. We use that subset because DOI matching gives us a conservative, high-confidence way to decide whether Elicit found the same paper.
Matching step | Share of listed studies |
|---|---|
Had at least one bibliography entry | 99.9% |
Matched to one unambiguous paper | 87.7% |
Had a DOI | 58.4% |
Matched to one unambiguous paper with a DOI | 56.7% |
Stage | Reviews |
|---|---|
Unique reviews in dataset | 994 |
With at least one parsed study record | 938 |
With at least one resolvable canonical DOI | 888 |
Our evaluations of search, abstract screening, and extraction each apply their own filters on top of this shared dataset of 888 studies / papers. Full-text screening uses a separately constructed Cochrane dataset, built with the same methodology, because that evaluation required full-text annotations and fetchable PDFs.
Search
Using only the review title as the query, Elicit finds 95.0% of included studies
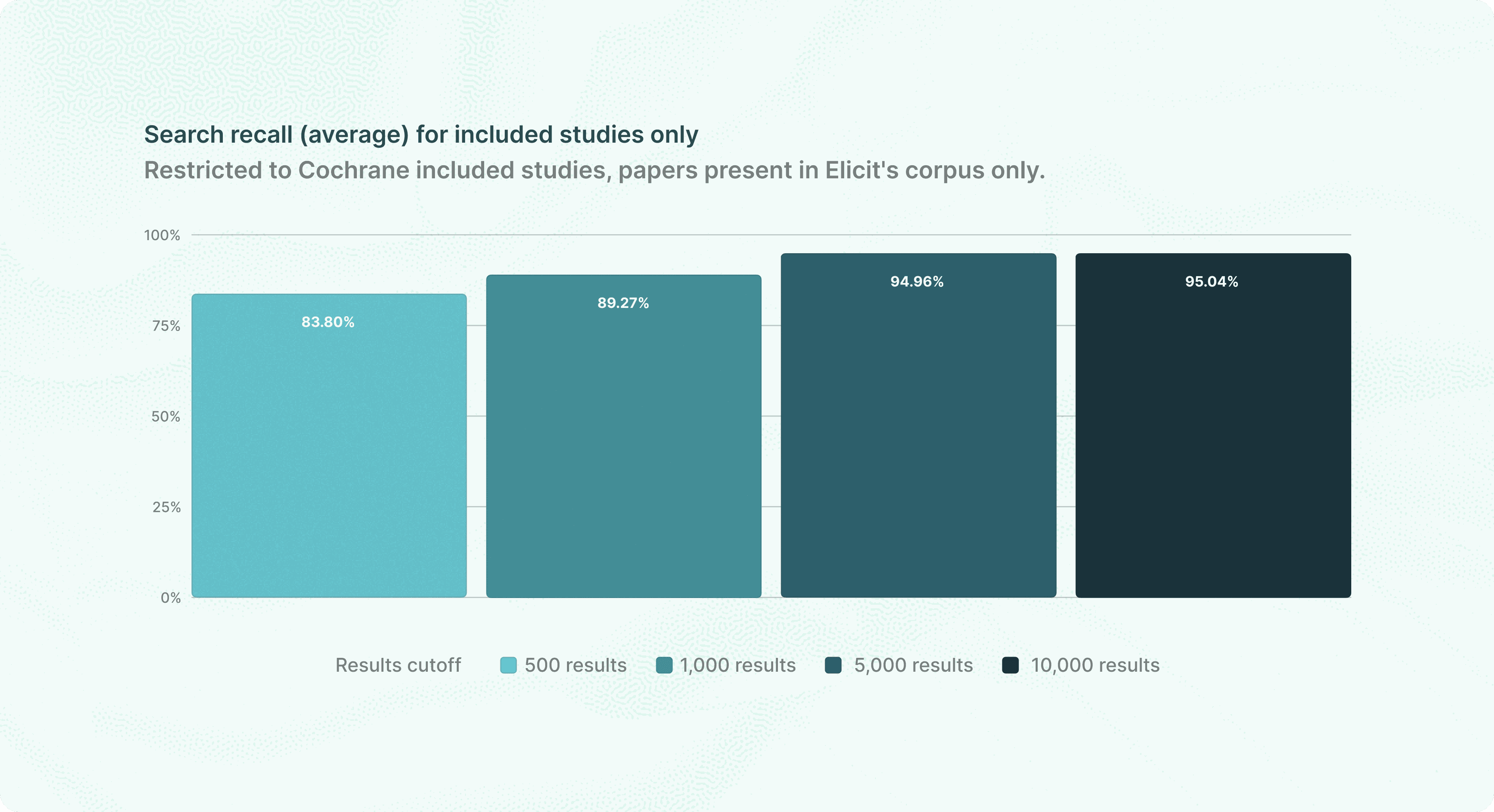
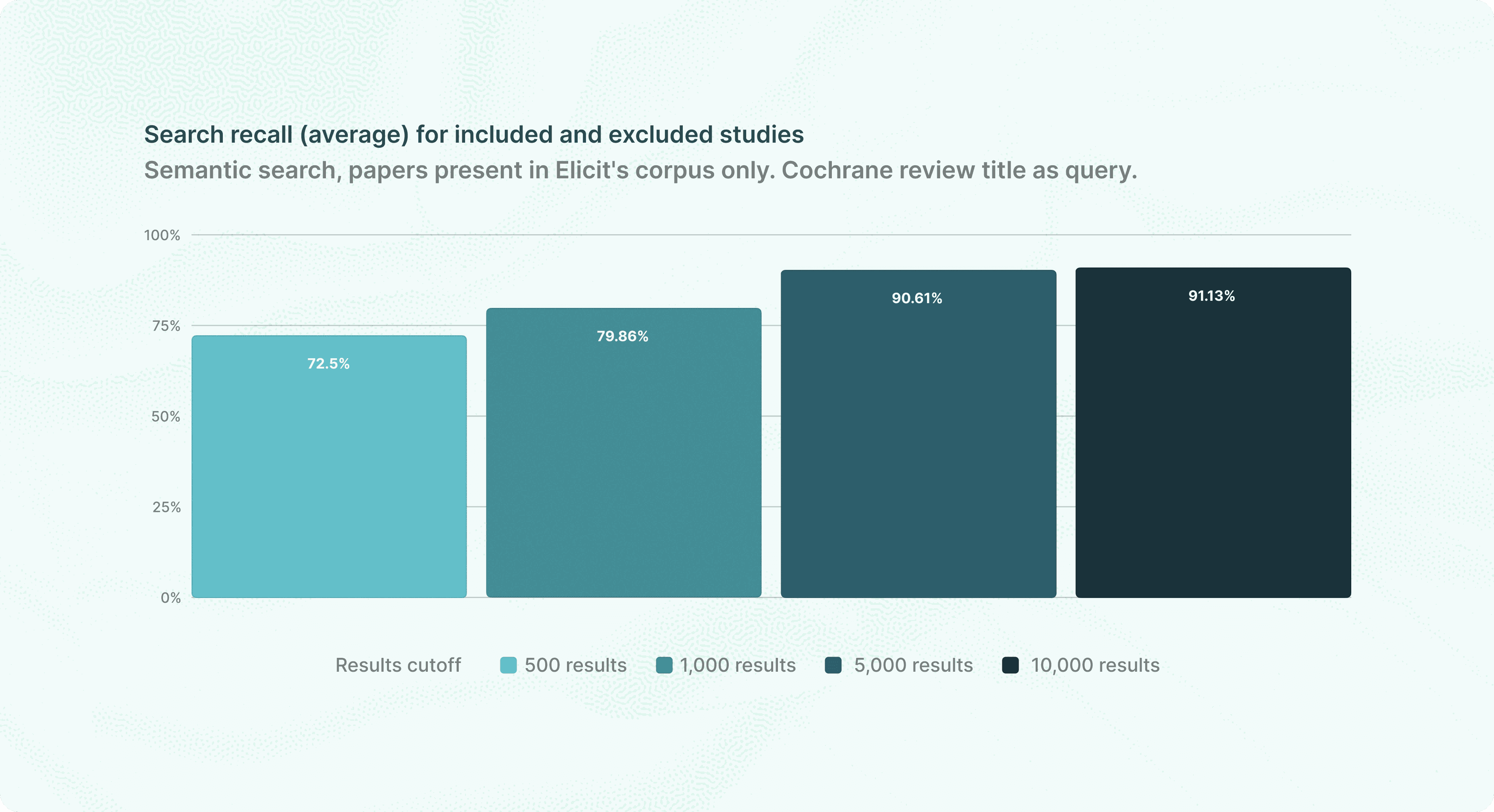
When we evaluate Elicit Search, we measure: given a systematic review question, can Elicit find all the papers relevant to that review? Elicit allows users to search over 138 million papers.
What we are benchmarking here is our semantic search. In semantic search, a query is passed to an embedding model, which encodes it into a vector representation. That vector is then matched against Elicit's corpus to find the most relevant results. We don’t evaluate keyword search as it is fully deterministic and the output depends on the keywords the user inputs.
We use the review title as the Elicit query and nothing else. This is a conservative way to evaluate Elicit. In practice, a user running a systematic review on Elicit would provide substantially more context than a title — they can ask an in-depth research question, add information about the protocol, and run multiple search strategies mixing keyword and semantic approaches.
What does "relevant" mean here? We consider all papers that the review lists as both included studies and excluded studies as these are studies that are either included in the final review, or in the judgement of the review’s authors would have been retrieved by the search or otherwise warranted full-text assessment.
Results
The graph at the beginning of this section shows the mean percentage of included papers retrieved per review. This graph shows the percentage of all papers (included and excluded) retrieved:
Additionally, 79.8% of reviews had 100% of their included studies found by our search, and an additional 11.6% of them had over 80% of their included studies found by their search. For about 2% of reviews we were unable to find more than 50% of papers.
Review recall threshold | % of reviews at or above threshold |
|---|---|
100% | 79.8% |
90% | 85.7% |
80% | 91.4% |
70% | 93.7% |
60% | 96.5% |
50% | 98.2% |
40% | 98.5% |
30% | 98.5% |
20% | 99.5% |
10% | 99.5% |
0% | 100.0% |
In Appendix 3 below, we share additional results from a robustness check including search dataset papers that did not have a DOI present, but that did have a PMID that we could ultimately resolve to a DOI.
Abstract Screening
Elicit achieved 96.9% sensitivity on abstract screening with 92.5% specificity
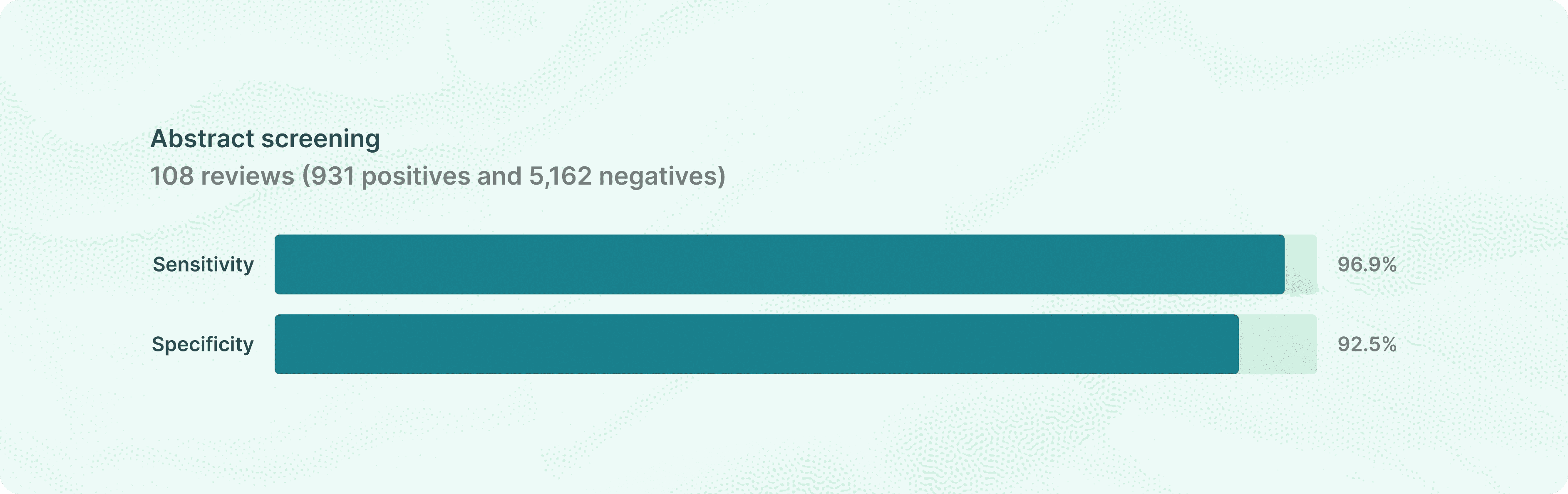
After search retrieves candidate papers, the next phase is abstract screening: given a review's eligibility criteria and a candidate paper's title and abstract, does Elicit correctly advance this paper to full-text review?
Starting from the shared dataset, we kept only reviews whose search strategies reported PubMed and MEDLINE search queries. We used a language model to translate each review's search syntax into PubMed syntax (if necessary). Then we ran each search in PubMed ESearch. We filtered out from the results all papers published after the review was published.
Then, for all of the reviews where a PubMed search result existed, we only kept those where the search results count was within 50% to 200% of the original PRISMA search results count. This was to avoid outliers where the PubMed search would be unrepresentative of the SLR’s actual search. From this subset, we further excluded reviews with fewer than five papers included or excluded. To create the negative set (papers that should be screened out), we randomly sampled 50 papers retrieved from the PubMed search strategy that weren’t in either the included or excluded tables in the review. This left us with 108 reviews.
On manual inspection, the excluded studies table was not a consistent proxy for abstract screening positives. Many papers in the excluded section violated the abstract screening criteria, and so we restricted the positive set to final-included studies only. We include examples in Appendix 7.
After filtering out papers whose abstracts were unavailable, 931 positives and 5,162 negatives made the final dataset. Our model makes a yes, no, or maybe decision on each screening criterion. If the paper is a "yes" or "maybe" on all criteria then it is screened in; if there are any "no"s it is screened out. We screen in maybes because it is much worse to miss a paper that should be included than it is to erroneously screen in a paper that will need to be screened out later at full-text screening.
Metric | Value |
|---|---|
Recall / sensitivity | 96.89% |
Specificity | 92.54% |
Precision | 70.09% |
Accuracy | 93.21% |
Elicit achieved 96.89% recall, 92.54% specificity, and 93.21% accuracy. In a study of human screening for pharmacological and public health reviews, Gartlehner et al. 2020 found that single-reviewer abstract screening achieved 86.6% sensitivity and dual-reviewer screening achieved 97.5%. Our dataset and evaluation approach are different from Gartlehner et al. 2020, and so we should approach comparisons with caution. Nevertheless, it is interesting to observe that our sensitivity exceeds their single-reviewer performance and approaches dual-reviewer screening. Specificity is harder to compare directly. Gartlehner et al.'s negatives are expert judgments from a systematic review. With that in mind, our specificity of 92.5% exceeds their 68.7% dual reviewer specificity.
Full-Text Screening
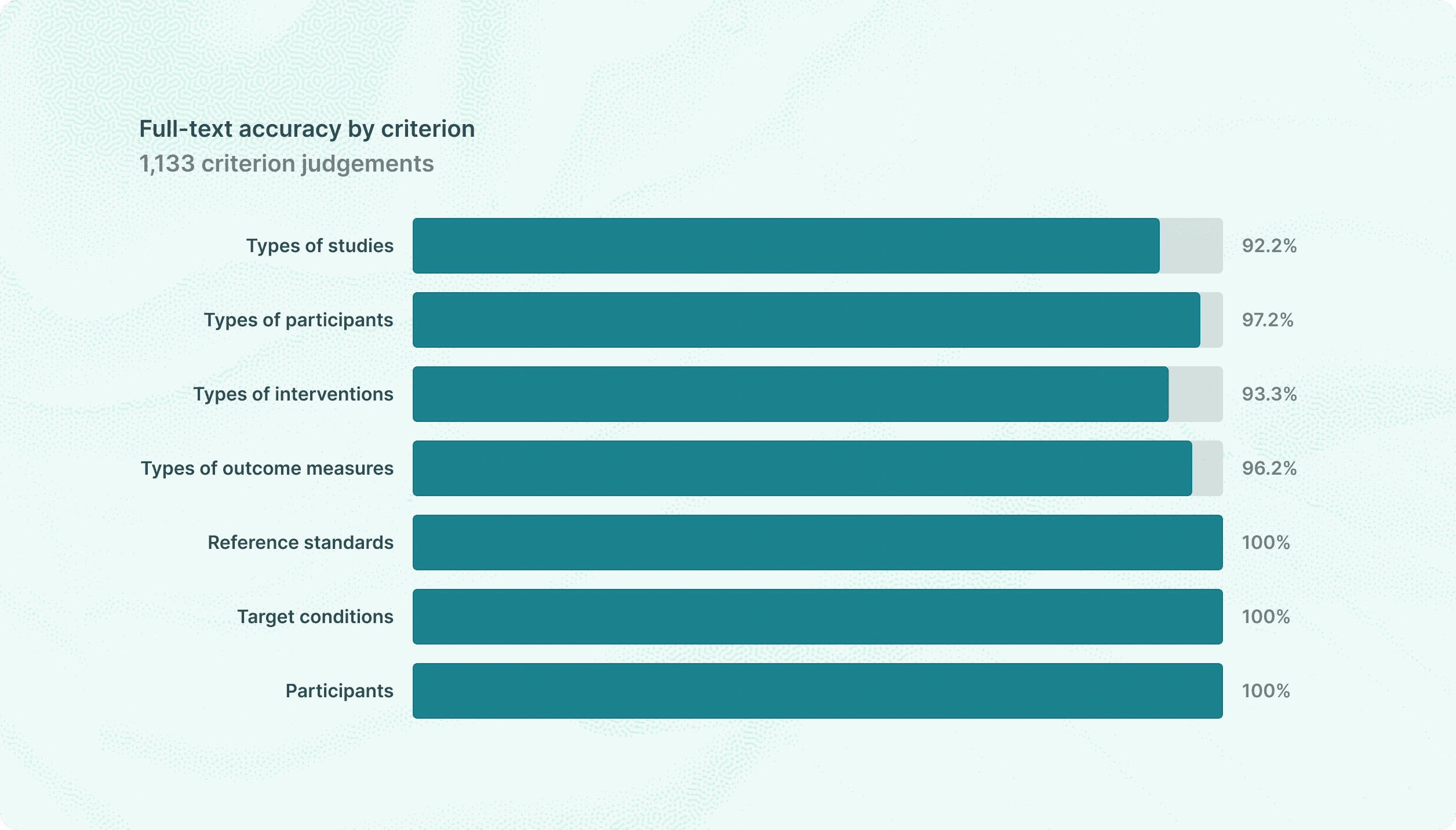
99.5% paper-level recall with 94.8% per-criterion accuracy

Full-text screening is the final gate before a paper enters the review. Abstract screening reviews titles and abstracts, full-text screening reads the entire paper and applies more detailed versions of the review's eligibility criteria.
Our full-text screening evaluation uses a separately constructed dataset built with the same round-robin sampling methodology across the same 12 MeSH areas, albeit with a smaller sample size of 100 reviews.
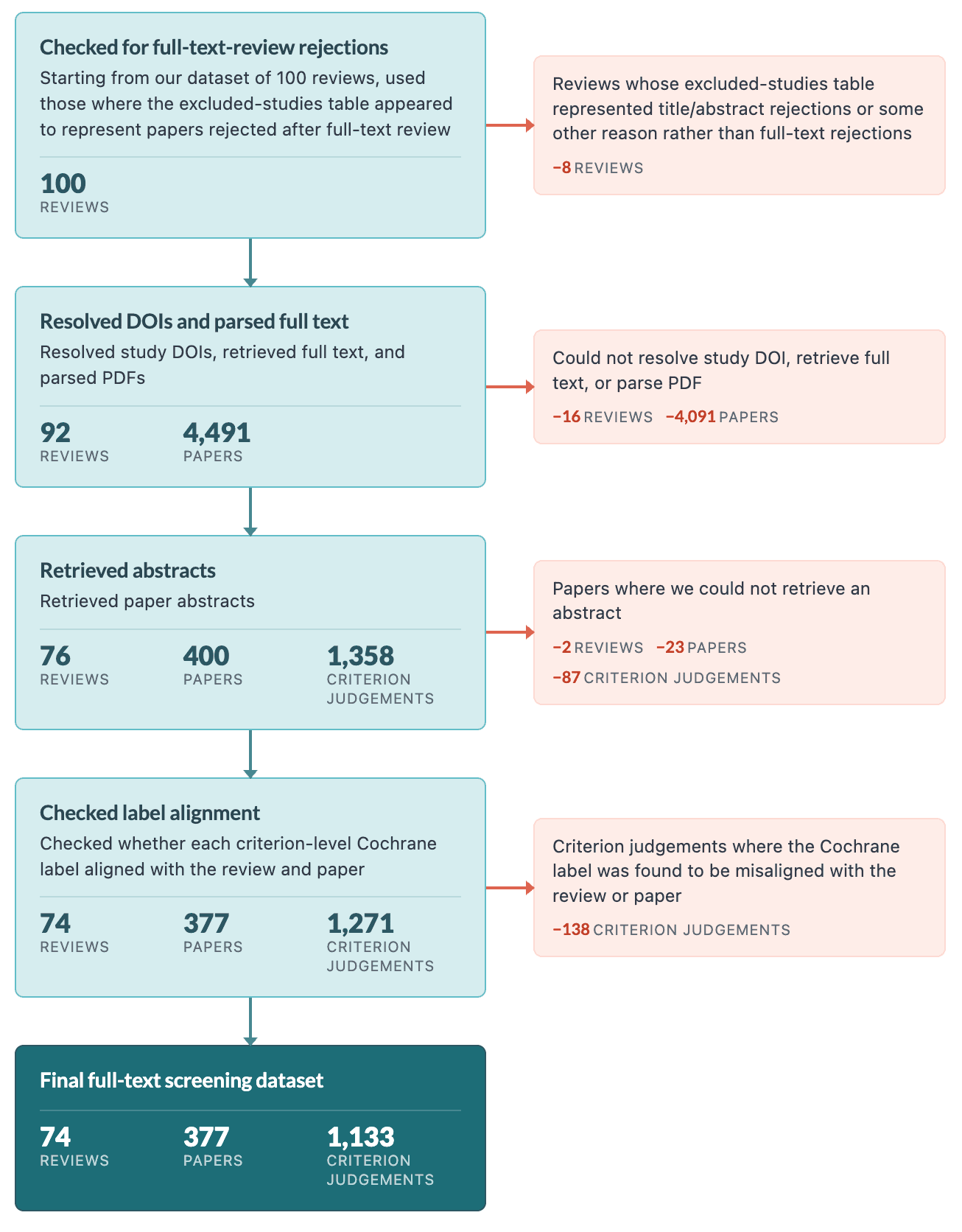
We then used reviews where the excluded-studies table appeared to represent papers rejected after full-text review, rather than papers rejected during title/abstract screening or papers listed for some other reason. After this check, the constructed label dataset contained 4,491 study rows across 92 reviews. To run the evaluation, we kept papers where we could resolve a study DOI, retrieve the paper full text, and parse the PDF. This produced 1,358 criterion-level screening examples across 400 papers and 76 reviews. We then dropped papers whose parsed source had no abstract text, leaving the final eval dataset: 1,271 criterion-level screening judgements across 377 papers and 74 reviews. The evaluation set is therefore much smaller than we would like, but it reflects a genuine constraint of working with full-text data.
While running the evaluation across multiple frontier and open-source models, we found 138 (10.9% of the dataset) screening judgements that all models consistently judged the opposite of the judgement in the Cochrane review. We manually examined roughly 30 of these and found they fell into two categories: cases where the review appeared to apply different screening criteria than the stated ones, and cases where we believe the reviewer was looking at a different paper than what the model saw as there are multiple papers that correspond to a study and we may have picked up on a different version. We excluded these from the final dataset.
Much as for abstract screening, we screen in papers judged as a “yes” or “maybe” on all criteria, and screen out studies judged as a “no” on at least one criterion.
At the paper level, sensitivity and specificity were:
Metric | Value |
|---|---|
Recall / sensitivity | 99.5% |
Specificity | 70.1% |
Precision | 81.2% |
Accuracy | 86.7% |
At the per-criterion level, our model evaluated 1,133 criterion-paper pairs with an overall accuracy of 94.8%:
Extraction
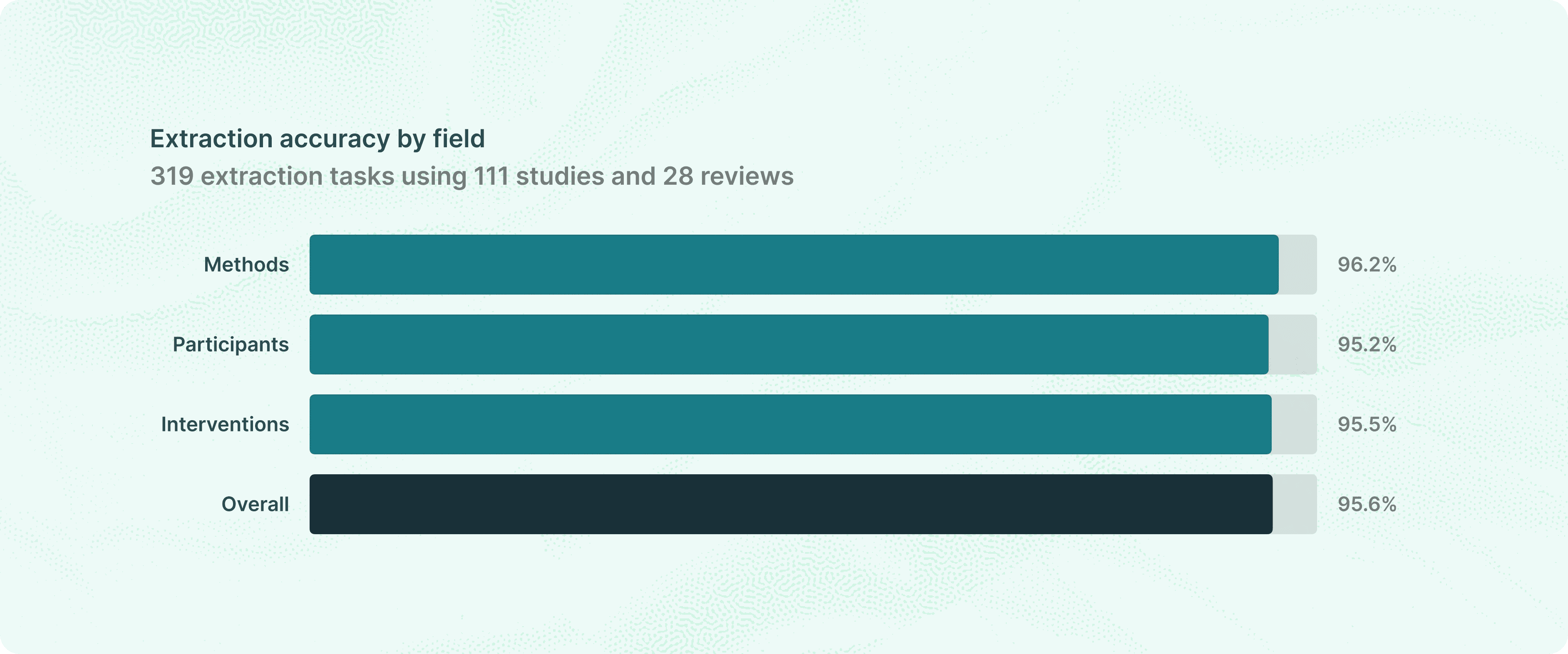
95.6% correct on Methods, Participants, and Interventions
The final stage of a systematic review is extraction: pulling structured information from each included paper. Cochrane reviewers do this manually, filling in "Characteristics of included studies" tables with fields like Methods, Participants, and Interventions for every paper in the review.
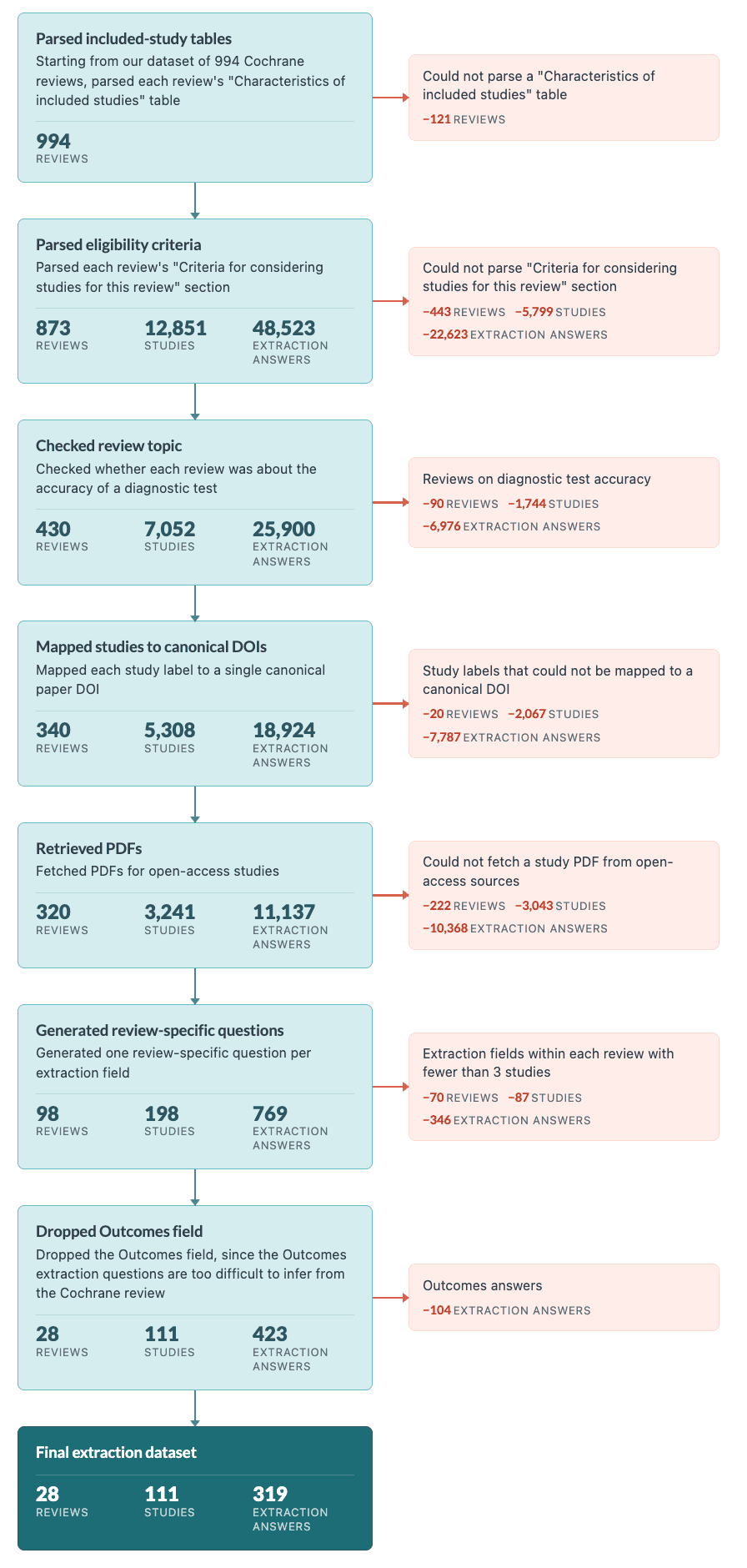
We used our 994 SLR corpus to create the evaluation dataset for extraction tasks. We first filtered for reviews that have a “Characteristics of included studies” table, leaving us with 873 reviews, and then filtered for reviews whose body had a section titled “Criteria for considering studies” leaving us with 430 reviews. We then kept reviews that weren’t diagnostic test accuracy reviews (which evaluate medical tests rather than interventions, and use a different data format), dropping us down to 340 reviews with 5,308 studies in the aggregate. Overall, these studies had 18,924 extraction answers. Then we filtered for studies which had a canonical DOI (as explained above) and were left with only 3,241 studies in 320 reviews. We then attempted to fetch PDFs from open-access sources, which succeeded for 198 studies across 98 reviews and 769 extraction answers.
When we manually looked at questions we realized that many questions were too generic when compared to the gold standards. A generic question like "who were the participants?" is not a faithful test of extraction quality. Each review defines its own data extraction schema: one might care about disease severity and sample size, another about age distribution and comorbidities. To reconstruct these review-specific questions, we asked a language model to look at the answers and infer what the review's extraction question was based on the answers.
We filtered to extraction fields with at least three accessible full-text extractions within each review to avoid overfitting to the answers. This is imperfect since the questions are reconstructed, not taken verbatim from protocols. Also, they may contain some clues as to the correct answers, though we tried to avoid this. The prompt used to generate the question and examples of the questions are in Appendices 8 and 9 below. And finally, we removed Outcomes because Cochrane gold answers inconsistently mix outcomes the paper reported with outcomes the review actually intended to extract, making it hard to define a clean review-specific extraction question.
On this benchmark, Elicit gets 95.6% of extraction tasks correct, as shown in the graph at the start of this section.
Each model answer was graded by a separate language model that saw the question, the Cochrane gold answer, the model answer, and the paper text.
We randomly selected 25 of the answers that were graded correct to review by hand. We agreed with the grade for all but one of the answers (which was an ambiguous case). We also reviewed by hand all 17 answers that were graded wrong, and agreed with the grade for 14/17.
Within the 42 total answers that we reviewed, there were 7 where it seemed like the data extraction in the Cochrane review may have been wrong (though it’s hard to tell without talking to review and study authors). There were another 5 where it seemed impossible to answer correctly based solely on the paper provided to the model, and the model would need additional or alternative papers about the study in question.
Conclusion
We found that Elicit achieved greater than 95% recall or accuracy at each stage of systematic review —
Search: 95.0% recall on included studies, using only the review title as the query.
Abstract screening: 96.9% sensitivity, beating single-reviewer humans and approaching dual-reviewer performance — at much higher specificity than the human comparator.
Full-text screening: 99.5% paper-level recall, 94.8% per-criterion accuracy.
Extraction: 95.6% correct on Methods, Participants, and Interventions.
We believe that Elicit is likely to perform well on a wide variety of systematic reviews.
What we learned about systematic reviews along the way
We (re-)learned that systematic reviews are complex and diverse, and that it isn’t possible to precisely reproduce a review just based on the information in the review itself. Cochrane reviews are known as the gold standard for evidence synthesis in health and beyond, and even Cochrane reviews contain heterogeneous excluded-studies tables, occasional screening and extraction errors, study records that resolve ambiguously across multiple papers, and screening and extraction methodology that is not explained in full detail.
Limitations
Extraction was on open-access studies only. PDF availability cut our extraction set from ~3,200 studies to ~200. Performance on paywalled literature could differ.
We evaluated semantic search only, not the full keyword + semantic workflow real users run. Recall would be higher if we added in keyword search results.
Full-text screening had a small n — 74 reviews, 377 papers — because it required both fetchable PDFs and reviews where excluded-studies tables reliably represented post-full-text decisions.
Extraction questions were reconstructed, not pulled from review protocols, since Cochrane doesn't publish the original extraction forms. We tried to avoid leaking the answer to the extraction model via these reconstructions, but we can’t rule out some amount of leakage.
Cochrane is one corpus. Our results may not fully generalize to non-Cochrane reviews, non-medical domains, and reviews with different methodological norms.
Appendices
These breakdowns are intended as diagnostic appendix material rather than headline claims. Some MeSH cells are small, so large swings in a category can reflect only a few papers.
Appendix 1: Search dataset size distribution
Source: completed 10k semantic search run over 859 successfully evaluated reviews. Included studies are Cochrane included study records with a resolved canonical DOI. Total relevant studies includes both included and excluded study records.
Statistic | Included studies per review | Total relevant studies per review |
|---|---|---|
Total studies | 7,532 | 21,436 |
Mean | 8.8 | 25.0 |
Median | 4 | 14 |
25th percentile | 2 | 6 |
75th percentile | 10 | 28 |
90th percentile | 21.2 | 57 |
Max | 240 | 705 |
Included studies per review | Reviews | Share of reviews |
|---|---|---|
0 | 112 | 13.0% |
1 | 101 | 11.8% |
2-5 | 266 | 31.0% |
6-10 | 167 | 19.4% |
11-25 | 150 | 17.5% |
26-50 | 50 | 5.8% |
51-100 | 11 | 1.3% |
101+ | 2 | 0.2% |
Total relevant studies per review | Reviews | Share of reviews |
|---|---|---|
1 | 40 | 4.7% |
2-5 | 147 | 17.1% |
6-10 | 170 | 19.8% |
11-25 | 248 | 28.9% |
26-50 | 155 | 18.0% |
51-100 | 73 | 8.5% |
101+ | 26 | 3.0% |
The typical review has 4 included studies and 14 total relevant studies, but the aggregate denominator is pulled upward by a long tail of large reviews. This is why per-review mean and median recall better match the user experience than aggregate recall.
Appendix 2: Search by MeSH area
Source: canonical semantic search run over the 888 DOI-scoreable reviews. All targets includes both Cochrane included and excluded study records. Included only uses Cochrane included study labels only. Both columns below report aggregate recall at 5,000 results.
MeSH area | Reviews | All targets | All raw | All in-index | Included targets | Included raw | Included in-index |
|---|---|---|---|---|---|---|---|
Cardiovascular | 73 | 1,530 | 73.4% | 78.2% | 462 | 81.4% | 86.2% |
Digestive | 73 | 1,859 | 80.2% | 88.9% | 698 | 88.5% | 94.6% |
Endocrine/Metabolic | 72 | 2,667 | 69.0% | 76.1% | 825 | 79.4% | 84.3% |
Eye | 77 | 1,358 | 77.4% | 82.8% | 584 | 85.6% | 89.9% |
Hematologic | 72 | 1,353 | 78.0% | 82.8% | 506 | 83.8% | 86.9% |
Immunologic | 78 | 2,307 | 76.3% | 82.5% | 567 | 91.7% | 95.2% |
MeSH area | Reviews | All targets | All raw | All in-index | Included targets | Included raw | Included in-index |
|---|---|---|---|---|---|---|---|
Infectious Disease | 72 | 2,302 | 78.0% | 85.3% | 687 | 89.1% | 94.2% |
Kidney | 77 | 2,329 | 66.2% | 70.9% | 997 | 77.4% | 82.0% |
Musculoskeletal | 74 | 1,428 | 78.2% | 84.0% | 602 | 87.4% | 91.0% |
Neoplasms | 75 | 2,049 | 76.1% | 81.7% | 668 | 86.4% | 90.9% |
Neurology | 73 | 1,187 | 79.0% | 84.6% | 501 | 87.2% | 93.8% |
Respiratory | 72 | 1,458 | 84.6% | 89.9% | 567 | 91.9% | 95.6% |
Appendix 3: Search results with papers identified by PMID
As a robustness check, we tried including in the search dataset papers that did not have a DOI present, but that did have a PMID that we could ultimately resolve to a DOI. This expands our dataset, but also lowers the dataset quality – we noticed that we sometimes resolved the PMID to an incorrect DOI. Therefore these results are harder to interpret.
DOI + PMID-linked matching
Top K | Mean included recall | Mean included+excluded recall |
|---|---|---|
500 | 79.06% | 66.85% |
1,000 | 84.24% | 73.62% |
5,000 | 89.69% | 83.73% |
10,000 | 89.77% | 84.21% |
Appendix 4: Abstract screening by MeSH area
Positives are Cochrane included studies; negatives are PubMed replay reject candidates. yes and maybe count as screen-positive.
MeSH area | Papers | Positives | Negatives | Sensitivity | Specificity | Precision | Accuracy |
|---|---|---|---|---|---|---|---|
Cardiovascular | 620 | 93 | 527 | 96.8% | 94.9% | 76.9% | 95.2% |
Digestive | 385 | 50 | 335 | 98.0% | 92.5% | 66.2% | 93.2% |
Endocrine/Metabolic | 510 | 77 | 433 | 98.7% | 93.3% | 72.4% | 94.1% |
Eye | 997 | 146 | 851 | 97.9% | 92.2% | 68.4% | 93.1% |
Hematologic | 217 | 72 | 145 | 97.2% | 91.0% | 84.3% | 93.1% |
Immunologic | 313 | 27 | 286 | 92.6% | 86.7% | 39.7% | 87.2% |
MeSH area | Papers | Positives | Negatives | Sensitivity | Specificity | Precision | Accuracy |
|---|---|---|---|---|---|---|---|
Infectious Disease | 555 | 76 | 479 | 93.4% | 89.8% | 59.2% | 90.3% |
Kidney | 409 | 68 | 341 | 98.5% | 91.2% | 69.1% | 92.4% |
Musculoskeletal | 739 | 117 | 622 | 94.0% | 93.9% | 74.3% | 93.9% |
Neoplasms | 406 | 69 | 337 | 100.0% | 91.7% | 71.1% | 93.1% |
Neurology | 557 | 71 | 486 | 97.2% | 94.4% | 71.9% | 94.8% |
Respiratory | 385 | 65 | 320 | 96.9% | 95.3% | 80.8% | 95.6% |
Appendix 5: Full-text screening by MeSH area
MeSH area | Papers | Included | Excluded | Sensitivity | Specificity | Precision | Accuracy |
|---|---|---|---|---|---|---|---|
Cardiovascular | 46 | 28 | 18 | 100.0% | 50.0% | 75.7% | 80.4% |
Digestive | 30 | 15 | 15 | 100.0% | 60.0% | 71.4% | 80.0% |
Endocrine/Metabolic | 29 | 19 | 10 | 100.0% | 80.0% | 90.5% | 93.1% |
Eye | 43 | 29 | 14 | 100.0% | 100.0% | 100.0% | 100.0% |
Hematologic | 7 | 6 | 1 | 100.0% | 100.0% | 100.0% | 100.0% |
Immunologic | 39 | 24 | 15 | 100.0% | 80.0% | 88.9% | 92.3% |
MeSH area | Papers | Included | Excluded | Sensitivity | Specificity | Precision | Accuracy |
|---|---|---|---|---|---|---|---|
Infectious Disease | 22 | 6 | 16 | 100.0% | 75.0% | 60.0% | 81.8% |
Kidney | 24 | 7 | 17 | 100.0% | 94.1% | 87.5% | 95.8% |
Musculoskeletal | 19 | 16 | 3 | 93.8% | 100.0% | 100.0% | 94.7% |
Neoplasms | 41 | 24 | 17 | 100.0% | 58.8% | 77.4% | 82.9% |
Neurology | 40 | 30 | 10 | 100.0% | 40.0% | 83.3% | 85.0% |
Respiratory | 37 | 9 | 28 | 100.0% | 60.7% | 45.0% | 70.3% |
Appendix 6: Extraction by MeSH area
MeSH area | Tasks | Correct | Accuracy |
|---|---|---|---|
Cardiovascular | 10 | 9 | 90.0% |
Digestive | 12 | 11 | 91.7% |
Endocrine/Metabolic | 36 | 34 | 94.4% |
Eye | 45 | 45 | 100.0% |
Hematologic | 30 | 30 | 100.0% |
Infectious Disease | 48 | 45 | 93.8% |
Kidney | 69 | 64 | 92.8% |
Musculoskeletal | 18 | 18 | 100.0% |
Neoplasms | 27 | 25 | 92.6% |
Neurology | 18 | 14 | 77.8% |
Respiratory | 6 | 6 | 100.0% |
Appendix 7: Excluded-studies table audit
For the abstract screening benchmark, we initially considered treating Cochrane's excluded-studies table as a source of screening positives: papers that were not included in the final review, but that plausibly made it far enough through the review process to warrant full-text assessment. On manual inspection, this was not consistently true. Some excluded-study records appeared to fail eligibility criteria that were visible from the title, abstract, or PubMed metadata alone.
The examples below illustrate why we restricted the final abstract-screening positive set to Cochrane included studies only. These are not errors in Cochrane's review process; they are cases where the excluded-studies table is too heterogeneous to serve as a clean proxy for abstract-screening positives. It can contain full-text exclusions, but also reviews, retrospective studies, observational studies, wrong-intervention papers, pharmacokinetic studies, and other records that an abstract screener could reasonably reject before full-text review.
Review | Excluded study | Review criterion it appears to fail | Why this looks abstract-rejectable |
|---|---|---|---|
Rifaximin for hepatic encephalopathy in cirrhosis | Ahire 2017, PMID 28799305 | Study design: randomized clinical trials only | The abstract and PubMed metadata identify it as an observational study; treatment was allocated by physician decision rather than randomization. |
Computed tomography for acute appendicitis in adults | Bendeck 2002, PMID 12354996 | Study design: prospective studies comparing CT with a reference standard | The abstract says medical records of consecutive appendectomy patients were retrospectively reviewed. |
Heavy menstrual bleeding in women with bleeding disorders | Halimeh 2012, PMID 22127528 | Study design: randomized controlled studies | The abstract is a background clinical article about menorrhagia and bleeding disorders, not a randomized intervention trial. |
Lamotrigine add-on therapy for drug-resistant generalized tonic-clonic seizures | Brzakovic 2012, PMID 22583007 | Intervention/design: lamotrigine add-on treatment versus placebo or active comparator in a randomized controlled trial | The abstract is a pharmacokinetic study of lamotrigine clearance and drug interactions, not an add-on efficacy trial. |
Community first responders for out-of-hospital cardiac arrest | Kellermann 1993, PMID 8411501 | Study design: randomized or quasi-randomized trials of EMS care with versus without community first responders | The abstract explicitly describes a nonrandomized controlled trial. |
Recombinant growth hormone for cystic fibrosis | Hardin 1997, PMID 9255232 | Study design: randomized or quasi-randomized controlled trials | The abstract describes registry/experience data from treated children with cystic fibrosis; Cochrane labels it a retrospective chart review. |
Appendix 8: Prompt used to generate synthetic questions for extraction
You are helping build a systematic review extraction benchmark for Cochrane reviews.
For a (Cochrane review, extraction field) pair, you will see a sample of ground-truth extractions from papers in the review. They demonstrate the reviewer's intent and level of detail, BUT their formatting is often wonky — typos, inconsistent capitalization, unusual punctuation, non-ASCII dashes (e.g. "‐" instead of "-"), stray whitespace. Do NOT defer to the wonky formatting.
Produce two things:
question — ONE concise, protocol-style question a reviewer would put on their extraction form for this field. Terse (one short clause), plain language, applicable to any paper in the review. Do NOT reverse-engineer specific facts from the examples.
example_answers — invent TWO OR THREE short, SYNTHETIC example answers that illustrate the range of plausible valid answers. These must be FABRICATED — do NOT copy or lightly paraphrase any of the sample extractions shown to you. They should illustrate variety: different shapes (e.g., brief vs more detailed), different kinds of content (e.g., positive findings, negative findings, compound designs), different phrasings. They are style/scope exemplars, not real answers. Use exemplary formatting — no typos, ASCII hyphens, correct capitalization, concise.
Respond using exactly these tags, in this order, with nothing else: <question>the question here</question> <example_answers>
first synthetic example
second synthetic example
third synthetic example (optional) </example_answers>
No preamble, no code fences, no trailing text.
Appendix 9: Examples of inferred questions in extraction evaluation
Example 1 — CD012633 (cancer-related anemia), Interventions field, 7 studies in group
Question: "What were the intervention details (drug name, dose, hemoglobin target, and planned duration)?"
Synthetic exemplars shown in instructions:
"Drug: darbepoetin alfa; Dose: 2.25 mcg/kg subcutaneously once weekly; Hb target: 11-13 g/dL; Duration: 16 weeks"
"Drug: epoetin beta; Dose: 30,000 IU subcutaneously once weekly; Hb target: 12-14 g/dL; Duration: 24 weeks"
Actual golds:
Boogaerts 2003 → "epoetin beta; 150 IU/kg sc, three times per week; 12-14 g/dL; 12 weeks"
Fujisaka 2011 → "epoetin beta; 36,000 IU/week; 12.0 g/dL; 12 weeks"
Moebus 2013 → "epoietin alfa; 450 IU/kg; 12.5-13 g/dL; 18 weeks".
Example 2 — CD000371 (deworming), Methods field, 4 studies in group
Question: "What is the study design, and if a cluster trial, what clustering details (adjustment method, cluster unit, average cluster size, ICCs) and length of follow-up are reported?"
Synthetic exemplars shown in instructions:
"RCT. Length of follow-up: 12 months"
"Cluster RCT. Method to adjust for clustering: generalized estimating equations. Cluster unit: school. Average cluster size: 30. ICCs: 0.05. Length of follow-up: 18 months"
Actual golds:
Ndibazza 2012 → "RCT; Length of follow-up: 5 years"
Yap 2014 → "RCT; Length of follow-up: 6 months"
Awasthi 1995 → "Cluster-quasi-RCT; Method to adjust for clustering: cluster used as unit of analysis; Cluster unit: urban slum; Average cluster size: 74; ICCs: not reported; Length of follow-up: 2 years"
Wiria 2013 → "Cluster RCT; Method to adjust for clustering: primary outcome of BMI was not adjusted for clustering; Cluster unit: household; Average cluster size: 4; ICCs: not reported; Length of follow-up: 21 months"
Example 3 — CD011469 (diabetes distress interventions), Participants field, 3 studies in group
Question: "What were the inclusion criteria, exclusion criteria, and diagnostic criteria for participants?"
Synthetic exemplars shown in instructions:
"Inclusion criteria: adults aged 18 years or older with type 2 diabetes for at least 6 months and HbA1c ≥ 7.5%. Exclusion criteria: severe mental illness, pregnancy, or inability to provide informed consent."
"Inclusion criteria: type 1 or type 2 diabetes, over 21 years of age, currently receiving insulin therapy. Exclusion criteria: active substance abuse, significant cognitive impairment, or participation in another trial."
Actual golds:
Dennick 2015 → "Inclusion: adults with type 2 diabetes aged ≥18 and diagnosed for ≥6 months. Exclusion: diagnosed psychiatric disorder, depression treatment, history of self-harm, or GP assessment as unsuitable; participants scoring ≥16 on CES-D."
Rosenbek 2011 → "Inclusion: type 1 or type 2 diabetes mellitus, over 18, had participated in a group education programme. Exclusion: pregnancy, severe debilitating disease, cognitive deficit. Diagnostic criteria: PAID, PCDS, HbA1c."
Simmons 2015 → "Inclusion: type 2 diabetes for ≥12 months. Exclusion: dementia or psychotic illness. Diagnostic criteria: PHQ-8, EQ5D, diabetes self-efficacy, RDKS, diabetes distress, medication adherence, HbA1c."


